
Retin.us - My Personal RSS Reader (source)
It's been a while since my last update on Retinus (original post). Not much has changed since then, the codebase has been quite robust and hasn't needed any maintenance. However I did promise in the previous post that I would go over how I built it, so I figured it would be a good time to go over the feature I added recently instead, which is a predicted article interest notification system using Naive Bayes classification.

Green means that I will probably be interested in this article,
and Red means that I will probably not be interested in the article. Simple.
I actually had a similar system in the form of a chrome extension for Google Reader (back when that was still a thing). The way it works it that it analyses patterns in my history, specifically it looks at the title, summary, and target links of articles which I have clicked on in the past (indicating interest), and it compares that to new articles for similarity. If there seems to be a correlation with the current article and what I clicked in the past, the classifier (Naive Bayes) returns a positive correlation, and I mark the article as interesting.
Now, before I go on, I will preface with the fact that this feature is currently turned on for everyone, however it classifies only based on my history. The reason for this is
- I am the only heavy user of my reader, which means I am the only one with enough click history to make accurate predictions for. And
- Computing and storing predictions is expensive (storage, memory, and computation), and I simply don't have the resources to maintain that kind of service for everyone (pro version?).
Anyways, lets begin with an introduction to Naive Bayes classification and go over basically how it works. I recommend you read other sources as well (and watch this video), but I will try to explain it from a high-level programmer perspective.
Naive Bayes works by assuming that all 'features' are independent (that's the Naive part). A 'feature' is an input. For example, lets say I have a cat dog with brown fur and floppy ears. Well then I may have two features I can use to compare him to other dogs - fur color (1) and ear floppiness (2). I can measure how floppy his ears are (and get a float/int) or I can measure if his ears are floppy (and get a boolean) (same for fur). However, we have to assume that these are independent. The fact that the dog is brown does not affect if his ears will be floppy (remember, Naive). It may be that in fact the features really are related (brown dogs have floppy ears) however, we ignore this fact in order to make computation reasonable (it's a CPU intensive computation).
Now, lets see how we can extract 'features' from text. Lets take the following string:
The dog sat down and the dog was happy.Alright, we can now break down the string into individual words (each word is a feature) (this is where you tokenize words, and can do thing like remove punctuation and add word combinations).
{
'the': 2,
'dog': 2,
'sat': 1,
'down': 1,
'and': 1,
'was': 1,
'happy': 1
}
Now, lets add another sentence to compare it to, and also label out two sentences differently.
// dog sentences 'dog': { 'the': 2, 'dog':2, 'sat':1, 'down':1, 'and':1, 'was':1, 'happy':1 }, // cat sentences: the cats like scratching 'cat': { 'the': 1, 'cats': 1, 'like': 1, 'scratching': 1 }
Ok, now we can try to classify a new sentence: 'the animal lay down at my feet'
{
'the':1,'animal':1,'lay':1,'down':1,'at':1,'my':1,'feet':1
}
// dog-ness score
2 + 1 + 1 = 4 ('the'*2, 'lay', 'down')
// cat ness score
1 = 1 ('the'*1)
And we can then see that the sentence is more 'dog-like' than 'cat-like' because it's score is higher when comparing to the dog sentence history. Now obviously we haven't taken into account total sentences per class, or normalization of variables, or other things which would give us better results, but you get the idea. Here is a proper implementation of what I just described in ~100 lines of javascript. That bit of code comes straight out of the library which I used to do the classifications.
While I think it's important to understand generally whats going on in an algorithm like this, I don't find it so interesting to re-write what others have already done (as it can get quite complicated, especially with how you group words together, and stemming). So I opted to use the 'natural' language processing library, which has a built in Naive Bayes classifier.
In addition the the Bayes classifier, it also has a Logistic Regression classifier which I looked at, and I also found this SVM library svmjs which I tried as well (it didn't really work out). I'll explain both real quick.
The Logistic Regression classifier was horribly slow compared to the Bayes classifier, because logistic regression does not assume that the 'features' (words) are independent of each other. The results were also not that much better than the Naive Bayes, so I decided not to use it. The way this type of classifier works (~150 lines source) is, well, I'm not really sure. I think about it like a super multi-dimensional graph, where each word lives in N dimensional space and input documents create lines in this space, and then to classify we create a line out of our input document and compare it to other lines in the space (I hope that made sense).
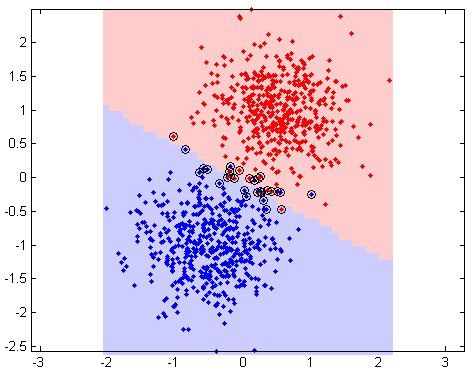
In addition to the logistic regression, I tried to use a Support vector machine (svm) to try to combine the results of many classifiers into a new, more accurate classifier. Besides the fact that the SVM library I chose to use didn't even work correctly (probably my fault), the SVM led to results that were sub-optimal for my particular problem (more on this in a sec). The way the SVM works, is that it takes an input matrix (array) of features and then tries to fit new matrices into either one of two groups (binary classification) by comparing it to matrices in its history.
Like so:
// train [1,1,1,0,0,0] 1 [1,0,1,0,0,0] 1 [0,0,0,1,1,1] -1 [0,0,1,1,0,1] -1 // test [0,1,1,0,0,0] == 1 [0,0,0,0,1,1] == -1
Now, as I mentioned before, I have 3 separate feature sets for rss feed items: title, summary, and link
My final solution was this:
var classifier1 = new natural.BayesClassifier() // summary var classifier2 = new natural.BayesClassifier() // title var classifier3 = new natural.BayesClassifier() // links // in a loop // train history based on hostname var hostname = url.parse(item.link).hostname.replace(/\./g,'_') classifier3.addDocument([hostname], isInteresting) // bayes text classifiers classifier1.addDocument(item.summary.toLowerCase(), isInteresting) classifier2.addDocument(item.title.toLowerCase(), isInteresting) // test var tag1 = classifier1.classify(docs[i].feedItem.summary.toLowerCase()) var tag2 = classifier2.classify(docs[i].feedItem.title.toLowerCase()) var tag3 = classifier3.classify(hostname) result = (tag1 === 'true' && tag3 === 'true' || tag2 === 'true' ? true : false)
Which gave me ~60% accuracy, with ~20% false negatives (I had ~4000 documents in my training set, and I separated 200 extra documents for testing, meaning that the classifiers were not trained on the 200 selected documents meant to check their accuracy). I care a lot about false negatives because a false negative means that an article was marked as uninteresting, when in fact I would have actually been interested in reading it. When I applied the SVM or combination Bayes classifier:
var classifierSum = new natural.BayesClassifier() // total // in a loop var tag1 = classifier1.classify(item.summary.toLowerCase()) var tag2 = classifier2.classify(item.title.toLowerCase()) var tag3 = classifier3.classify(hostname) classifierSum.addDocument([tag1,tag2,tag3], isInteresting) // test var tag1 = classifier1.classify(item.summary.toLowerCase()) var tag2 = classifier2.classify(item.title.toLowerCase()) var tag3 = classifier3.classify(hostname) result = classifierSum.classify([tag1, tag2, tag3])
I ended up with 90% accuracy, but also 100% false negatives (it marked everything as uninteresting). 90% is technically better than 60%, but having so many false negatives was not optimal for my problem.
That about covers the machine learning aspect of Retin.us so far, over the next few weeks I will be assessing its accuracy, and may eventually use it to pre-filter out uninteresting articles so as to save me time. As for the rest of the software stack, basically it uses Sails.js (home page), MongoDB, and Backbone (the Sails version is quite outdated, but the backbone code is decent to learn from).

